Важно, что религиозные ученые не остановились в своем исследовании на уровне слов. Они также проанализировали отдельные буквы; в частности, они выяснили, что некоторые буквы встречаются чаще других.
В арабском языке наиболее распространенными буквами являются a и l, отчасти из-за определенного артикля аl-, в то время как буква j занимает только десятое место по частоте появления. Это на первый взгляд безобидное наблюдение привело к первому значительному прорыву в криптоанализе.
Кто первым догадался, что изменение частоты появления букв может быть использовано в целях взлома шифров, неизвестно, но наиболее раннее из известных описаний этого метода датировано IX веком и принадлежит перу одного из крупнейших ученых Абу Юсуф Якуб ибн Исхак ибн ас-Сабах ибн Умран ибн Исмаил аль-Кинди. Известный как «философ арабского мира», аль-Кинди был автором 290 книг по медицине, астрономии, математике, лингвистике и музыке. Его самый знаменитый трактат, который был обнаружен заново лишь в 1987 году в оттоманском архиве Сулайманийа в Стамбуле, озаглавлен «Рукопись по дешифрованию криптографических сообщений», первая страница которой показана на рисунке 6. Хотя в нем содержится подробный анализ статистики, фонетики и синтаксиса арабского языка, революционная система криптоанализа аль-Кинди умещается в два коротких абзаца:
Один из способов прочесть зашифрованное сообщение, если мы знаем язык, на котором оно написано, — это взять другой незашифрованный текст на том же языке, размером на страницу или около того, и затем подсчитать появление в нем каждой из букв. Назовем наиболее часто встречающуюся букву «первой», букву, которая по частоте появления стоит на втором месте, назовем «вторая», букву, которая по частоте появления стоит на третьем месте, назовем «третья» и так далее, пока не будут сочтены все различные буквы в незашифрованном тексте.
Затем посмотрим на зашифрованный текст, который мы хотим прочитать, и таким же способом проведем сортировку его символов. Найдем наиболее часто встречающийся символ и заменим его «первой» буквой незашифрованного текста, второй по частоте появления символ заменим «второй» буквой, третий по частоте появления символ заменим «третьей» буквой и так далее, пока не будут заменены все символы зашифрованного сообщения, которое мы хотим дешифровать.
Объяснение аль-Кинди гораздо проще показать на примере английского алфавита. Прежде всего необходимо взять достаточно большой кусок обычного английского текста, может быть, несколько текстов, чтобы установить частоту появления каждой буквы алфавита. Наиболее часто встречающейся буквой в английском алфавите является буква е, затем идут буквы t, а и т. д. (см. таблицу 1). Затем возьмите интересующий вас зашифрованный текст и подсчитайте частоту появления каждой буквы в нем.

Рис. 6 Первая страница «Рукописи по дешифрованию криптографических сообщений аль-Кинди», в которой содержится самое первое из дошедших до нас описаний криптоанализа с помощью частотного анализа. Если, например, в зашифрованном тексте самой часто встречающейся буквой будет J, то, по всей видимости, она заменяет букву е. Если второй по частоте появления буквой в зашифрованном тексте будет Р, то вполне вероятно, что она заменяет букву t, и так далее. Способ аль-Кинди, известный как частотный анализ, показывает, что нет никакой необходимости проверять каждый из биллионов возможных ключей. Вместо этого можно прочесть зашифрованное сообщение просто путем анализа частоты появления букв в зашифрованном тексте.
Однако не следует безоговорочно применять принцип аль-Кинди для криптоанализа, поскольку в таблице 1 указаны только усредненные частоты появления букв, а они не будут в точности совпадать с частотами появления этих же букв в любом другом тексте. К примеру, краткое сообщение, в котором обсуждается влияние состояния атмосферы на передвижение полосатых четвероногих животных в Африке, «From Zanzibar to Zambia and Zaire, ozone zones make zebras run zany zigzags» не поддалось бы непосредственному применению частотного анализа. Вообще говоря, частота появления букв в коротком тексте значительно отклоняется от стандартной, и если в сообщении меньше ста букв, то его дешифрование окажется очень затруднительным. В то же время в более длинных текстах частота появления оукв будет приближаться к стандартной, хотя это происходит и не всегда.

Таблица 1 Таблица относительной частоты появления букв на основе отрывков, взятых из газет и романов; общее количество знаков в отрывках составляло 100 362 буквы. Таблица была составлена X. Бекером и Ф. Пайпером и впервые опубликована в «Системах шифрования: защита связи»
В 1969 году французский автор Жорж Перек написал 200-страничный роман «Исчезновение» («La Disparition»), в котором не было слов с буквой е. Вдвойне примечательно то, что английскому писателю-романисту и критику Гилберту Адэру удалось перевести «La Disparition» на английский язык, где по-прежнему, как и у Перека, буква е отсутствовала. Как ни удивительно, но перевод Адэра, под названием «А Void», является удобочитаемым (см. Приложение А). Если бы весь этот роман был зашифрован с помощью одноалфавитного шифра замены, то попытка дешифровать его оказалась бы безуспешной из-за полного отсутствия наиболее часто встречающейся буквы в английском алфавите.
Дав описание первого инструмента криптоанализа, я продолжу примером того, как частотный анализ применяется для дешифрования зашифрованного текста. Я старался не усеивать книгу примерами криптоанализа, но для частотного анализа я сделаю исключение. Частично потому, что частотный анализ не столь труден, как может показаться из его названия, а частично потому, что это основной криптоаналитический инструмент. Кроме того, последующий пример дает понимание принципа работы криптоаналитика. Хотя частотный анализ требует логического мышления, вы увидите, что необходимы также интуиция, гибкость ума и везение.
Криптоанализ зашифрованного текста
Предположим, что мы перехватили это зашифрованное сообщение. Задача состоит в том, чтобы дешифровать его. Мы знаем, что текст написан на английском языке и что он зашифрован с помощью одноалфавитного шифра замены, но мы ничего не знаем о ключе. Поиск всех возможных ключей практически невыполним, поэтому нам следует применить частотный анализ. Далее мы шаг за шагом будем выполнять криптоанализ зашифрованного текста, но если вы чувствуете уверенность в своих силах, то можете попытаться провести криптоанализ самостоятельно.
При виде такого зашифрованного текста любой криптоаналитик немедленно приступит к анализу частоты появления всех букв; его результат приведен в таблице 2. Нет ничего удивительного в том, что частотность букв различна. Вопрос заключается в том, можем ли мы на основе частотности букв установить, какой букве алфавита соответствует каждая из букв зашифрованного текста. Зашифрованный текст сравнительно короткий, поэтому мы не можем непосредственно применять частотный анализ. Было бы наивным предполагать, что наиболее часто встречающаяся в зашифрованном тексте буква О является и наиболее часто встречающейся буквой в английском языке — е или что восьмая по частоте появления в зашифрованном тексте буква Y соответствует восьмой по частоте появления в английском языке букве h. Бездумное применение частотного анализа приведет к появлению тарабарщины. Например, первое слово РС<2 будет расшифровано как аоv.
Таблица 2 Частотный анализ зашифрованного сообщения.
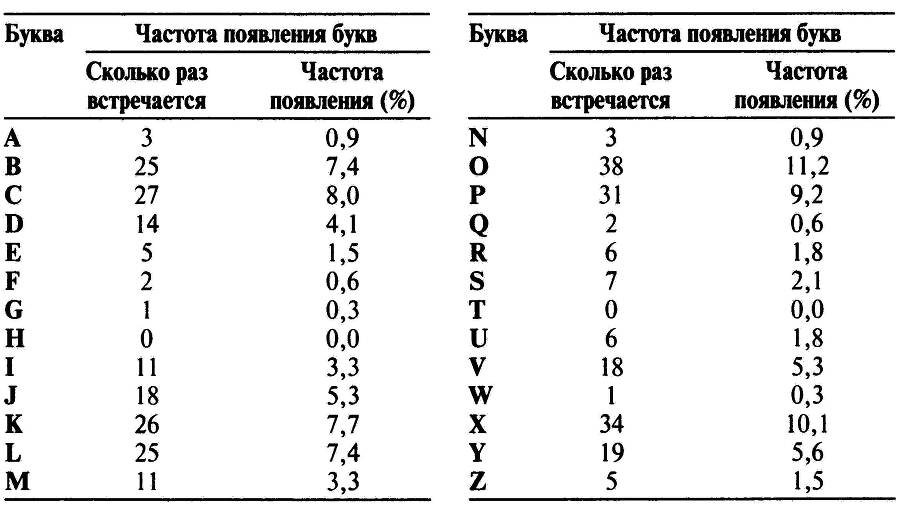
Начнем, однако, с того, что обратим внимание только на три буквы, которые в зашифрованном тексте появляются более тридцати раз: О, X и Р. Естественно предположить, что эти наиболее часто встречающиеся в зашифрованном тексте буквы представляют собой, по всей видимости, наиболее часто встречающиеся буквы английского алфавита, но не обязательно в том же порядке. Другими словами, мы не можем быть уверены, что О = е, X = t и Р = а, но мы можем сделать гипотетическое допущение, что: