Тут есть тонкости. Во-первых, старайтесь избегать повторных объявлений. Некоторые соискатели работы настолько нервные, что дают объявление по нескольку раз. Вам эти данные, конечно, не нужны.
Во-вторых, старайтесь не выходить за пределы своего сегмента рынка. Например, вы анализируете рынок труда главных бухгалтеров для средней российской торгово-промышленной компании. Вам наверняка попадутся объявления о поиске главбуха — финансового директора для какой-нибудь корпорации-монстра, владеющей сетью супермаркетов[50], для банка, для иностранной компании. Или, наоборот, какая-то дама ищет работу по совместительству в мелкой фирмешке или у ПБОЮЛа. Это тоже не наш контингент.
Итак, вы получили два столбика цифр: данные по спросу и по предложению на рынке труда. Дальше начинается самое интересное — анализ результатов.
Я полагаю, что читатели в основном знакомы с программой Excel и умеют обращаться с электронными таблицами. Но нам понадобятся некоторые функции этой программы, которые известны далеко не всем, поэтому я расскажу о них подробно.
Мы получили два массива чисел, из которых можно пока сделать только один вывод: сравнить их количество. Если оно примерно одинаково (с разбросом в 10-15%), значит, в целом спрос на рынке труда по анализируемой нами профессии в целом соответствует предложению. Именно в целом, потому что более тонкий анализ может вскрыть интересные несоответствия (см. главу «Вы на рынке труда»). И наоборот, может оказаться, что спрос выше или ниже предложения.
Для начала дадим нашим двум массивам имена: те же самые «спрос» и «предложение». Это нам пригодится в дальнейшем. Если вы не умеете присваивать имена диапазонам клеток в Excel — прочитайте в учебнике или в «хелпе», там все достаточно просто.
Наши два столбика чисел сами по себе ни о чем не говорят: их надо привести в вид, удобный для анализа. Это значит, сделать из них такую таблицу:
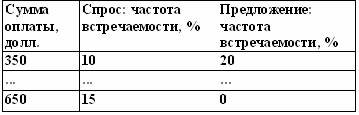
Если вы уверены, что легко и быстро справитесь с этой задачей, то можете смело пропустить следующие 4 страницы. Если нет — советую прочитать, хотя они больше относятся к работе с программой Excel, чем к управлению персоналом.
Для начала отсортируем оба столбика по возрастанию. Это делается совсем просто: в меню «данные» — «сортировка». Теперь мы видим две важные вещи: верхние и нижние границы диапазонов оплаты труда по спросу и по предложению, а также «шаг» их увеличения. В нашем гипотетическом примере диапазон невелик: минимум — 350 долларов, максимум — 650.
В большинстве случаев этот шаг бывает кратным 50 или 100 долларам. Но иногда бывает, что для красоты выборку приходится немного подчистить. Например, если попадаются суммы, скажем, в 170 или 120 долларов. Такие я просто предлагаю округлять в большую или меньшую сторону: нас ведь интересуют тенденции, а не точные значения!
Дальше мы делаем следующее. Создайте на том же листе Excel справа от наших двух столбиков (но отступя несколько столбцов, чтобы не запутаться) массив чисел, содержащий все значения уровней оплаты труда с установленным «шагом» (лучше всего — в 50 долларов). Он должен начинаться с минимального из имеющихся значений и кончаться максимальным. Это будет первая колонка нашей итоговой таблицы «Сумма оплаты, долл.». Можно, конечно, «набить» ее вручную, но проще воспользоваться функцией Excel «автозаполнение». Для этого введите первое и второе числа, например, 100 и 150, затем выделите обе клетки, удерживая пальцем левую клавишу мышки. Вы увидите, что курсор из толстого белого креста превратится в тонкий черный, а в нижнем правом углу выделенного вами диапазона появится маленький квадратик. Установите на него курсор при отпущенной клавише мышки, снова нажмите на клавишу и «протащите» диапазон вниз на десяток клеток. Вот и все! Ваш диапазон заполнился числами с необходимым «шагом». Остается только убрать или добавить снизу (таким же способом) несколько чисел, если вы промахнулись с их количеством.
Теперь нам надо справа от полученного первого столбца нашей итоговой таблицы для каждого значения уровня оплаты труда указать, сколько раз оно встречается среди данных по спросу и по предложению. Можно сделать это тупо вручную, но я предлагаю вам воспользоваться еще одной очень удобной функцией Excel: СЧЁТЕСЛИ.
Эта функция делает вот что: подсчитывает в указанном нами диапазоне количество чисел, совпадающих с определенным числом. То есть именно то, что нам надо!
Делается это так. Установите курсор на ячейку справа от верхней ячейки нашего диапазона уровней оплаты труда. Теперь выберите в меню «вставка» команду «функция» (она также обозначена символом f). Вы открыли экран «мастер функций», состоящий из двух окон. Выберите в левом окне команду «статистические» и в правом — СЧЁТЕСЛИ.
Перед вами появилось окно, куда следует вставить диапазон и условие. Вот тут-то нам и пригодятся имена, присвоенные нашим данным: «спрос» и «предложение». Щелкните мышкой в поле «диапазон», затем выберите в меню «вставка» команду «имя». Появится окно со всеми именами диапазонов, которые есть в нашем листе Excel. Выберите имя «спрос», и оно появится в поле «диапазон». Теперь перейдите в поле «условие» и укажите в нем адрес верхней ячейки диапазона уровней оплаты труда (то есть слева от той, куда вы сейчас вставляете функцию СЧЁТЕСЛИ). Теперь — ОК, и работа закончена, функция вставлена. На экране в этой ячейке вы увидите количество чисел из диапазона «спрос», равных тому, что находится в первой ячейке диапазона уровней оплаты труда. Теперь достаточно скопировать эту ячейку сверху вниз на весь столбец таблицы, и вы получите желаемое.
Тут есть хитрость, которую не все знают. Дело в том, что Excel, копируя ячейки, содержащие функции со ссылками на другие ячейки, по умолчанию использует не абсолютную, а относительную адресацию. Это значит, что в функции СЧЁТЕСЛИ, которую вы скопировали одной ячейкой ниже, адрес ячейки, содержащей условие счета, также окажется на строку ниже, как это нам и надо. Но зато группа ячеек «диапазон» тоже получится не заданной, а на строку ниже! Представляете себе, какие данные вы получите, сделав такую ошибку? Я точно знаю, потому что она типична для всех, кого я обучал своей методике. Поэтому и рекомендую использовать имена диапазонов вместо адресов: они-то уж точно никак не изменятся!
Вот какая табличка у вас получится:
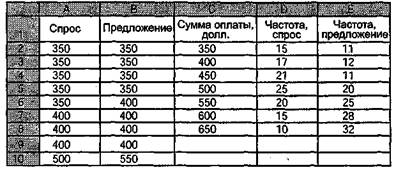
Обратите внимание: в столбцах вашей таблички «Частота, спрос» и «Частота, предложение» (столбцы D и Е) вы видите числа, показывающие, сколько раз соответствующая сумма оплаты (столбец С) встречается в «сырых данных» («Спрос» и «Предложение»). Но если вы выберете курсором любую ячейку в этих столбцах, то сверху, на панели формул, вы увидите что-то вроде «=СЧЁТЕСЛИ (Cпpoc;D3)» или «=СЧЁТЕСЛИ(Предложение;D3)», потому что в действительности в этой ячейке находится не число, а функция «СЧЁТЕСЛИ» с соответствующими адресами аргументов. И если какие-либо данные в столбцах «Спрос» и «Предложение» будут изменены, результаты мгновенно будут пересчитаны! Если хотите, можете проверить.
Наш следующий шаг — пересчитать полученные нами частоты встречаемости в проценты. Для этого сначала подсчитаем суммы по столбцам «Спрос» и «Предложение»; ведь количество данных по этим показателям может быть не одинаковым. Ну, как в Excel считать сумму по столбцам и переводить абсолютные показатели в проценты, вы, наверное, знаете.
Вот что у вас должно получиться в итоге:
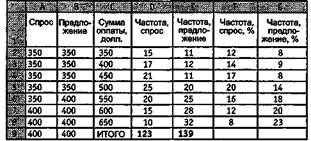
Смотрите: столбцы С, F и G — это и есть итоговая таблица, ради которой мы проделали все предыдущие процедуры! Остальные столбцы нам уже и не нужны. Теперь мы можем привести табличку в окончательный вид, вот такой:
50
Думаете, в Интернете таких не ищут? Еще как ищут: все приводимые здесь примеры я взял из практики!