СОФТЕРРА: Три вопроса
Автор: Константин Курбатов
К концу лета возвращаются домой с каникул/из отпусков стайки студентов, белых воротничков и редакторов еженедельных журналов. И пока студенты пытаются вспомнить имена преподавателей, а белые воротнички лихорадочно восстанавливают навыки скоростного набора текста и игры в пасьянс, редакторы еженедельных журналов вдруг обнаруживают новые версии программного обеспечения, требующие немедленного обзора…
Как известно, формат PDF замечателен тем, что на любом компьютере вы видите оформление текста именно таким, каким его задумывал создатель файла. Беда в том, что нередко мы бы желали, чтобы файл был задуман в формате Word, в крайнем случае Excel, а некоторые любители изящной словесности предпочли бы TXT.
Для разрешения этого экзистенциального противоречия компания ABBYY выпустила уже вторую версию своей утилиты PDF Transformer. Но кому нужна утилита для конвертирования файлов из PDF в текстовый формат, когда прямо в Acrobat Reader можно выделить текст и перенести его в любую программу через буфер обмена?
На самом деле загвоздка бывает с теми файлами, в которых нет никакого текста. Точнее, текст в них представлен в виде растрового изображения, и поэтому желание «ткнуть сюда мышкой» и скопировать кулинарный рецепт в «аську» обычно встречает угрюмое непонимание «Акробата». И тут наш преобразователь, поигрывая мускулами своего старшего брата [Или, наверное, дяди?] FineReader’а, такой текст с легкостью распознает (37 языков, включая, разумеется, албанский) и помещает в итоговый DOC-, RTF-, XLS-, TXT-, HTML-… или опять в PDF-файл, но уже с текстовым слоем [Так называемый Searchable PDF, который может быть проиндексирован поисковиком, а текст из него можно копировать обычным образом через буфер обмена].
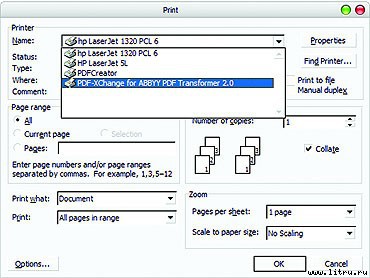
Кроме того, в новой версии появился «виртуальный PDF-принтер» (рис. 1), благодаря которому счастливые пользователи получили возможность создавать свои собственные непригодные для редактирования документы.
Как ни странно, возможность «печатать» в PDF оказалась очень удобной для записи на диск нужных веб-страниц. Все ссылки с них сохраняются и продолжают работать [Кстати, это верно и наоборот: ссылки из PDF переходят в итоговый документ, включая сноски и оглавление]. А возможность за пару кликов отправить этот файл по электронной почте, вообще удивительно удобная штука — белые воротнички, лишенные http-доступа на работе, будут вам безмерно благодарны. Кстати, размер такого файла можно регулировать за счет качества сохраняемых картинок, поэтому веб-страницы с многомегабайтными картинками легко можно уложить в 3—4-мегабайтный PDF. Еще одно применение — распознавание документов, хранящихся в виде обычных сканов (например, тексты патентов в Интернете), — вы просто «печатаете» их в PDF, а затем конвертируете его в доступный для редактирования формат (RTF, HTML), причем вместе со всеми прилагающимися схемками и иллюстрациями.
Я попробовал распознать и перевести в HTML-форму один из недавних материалов нашего журнала, для того чтобы его можно было выложить на сайт. Подписи к иллюстрациям достаточно красноречивы, но хотелось бы сделать несколько замечаний.
Во-первых, разрывы колонок воспринимаются программой как разрывы абзацев, поэтому если между ними был перенос слова, его надо вручную корректировать. Во-вторых, обрабатывая сложно сверстанный PDF-файл, программа постоянно ошибалась при автоматическом выборе порядка следования текстовых блоков, в результате многоколоночный текст с иллюстрациями сильно перемешивался. И это одна из главных причин, почему в новой версии появился интерфейс, в котором можно управлять разбиением на блоки. В-третьих, часто диаграммы определяются как таблицы из-за регулярных фоновых квадратиков, и в этом случае ручной режим просто необходим (рис. 3). И наконец, не могу не сказать о хорошем качестве распознавания на пестром разноцветном фоне. Не претендуя на объективность оценки, я тем не менее должен отметить практически полное отсутствие ошибок (рис. 2).

Итак, за 1490 рублей пользователь получает немало дополнительных функций, которые полностью оправдывают удорожание программы (за первую версию просили 830 рублей) [Любопытно, что лицензия позволяет установить программу на два компьютера — домашний и, например, ваш мобильный или рабочий].
А вот на вопрос, действительно ли это вам нужно, я предлагаю ответить самостоятельно…
Точное сохранение оформления документа
Это не новшество, то же самое делала и первая версия. Но теперь у программы появился некий интерфейс, который можно вызвать, если выбрать «конвертировать, используя пользовательские настройки». В этом случае пред вашим взором предстанет чудное окошко (рис. 4), где в левой части можно видеть странички PDF-файла, а в правой — «куда ставить-то», то есть формат, параметры конвертации и папку для итогового файла. Вся прелесть этого режима в том, что можно не только собственноручно выбирать области распознавания (выбрасывая, например, колонтитулы) и их тип [Это особенно важно для выбора таблица/картинка, так как некоторые картинки с регулярными прямоугольниками (графики) программа объявляет таблицей], но и порядок распознавания блоков (рис. 5), что особенно помогает, когда файл представляет собой сложный многоколоночный текст.

Варианты сохранения оформления документов
Так как появилась возможность манипулировать блоками, разработчики реализовали некоторые характерные сценарии преобразования в виде отдельных опций. При сохранении в формате Microsoft Excel можно, например, выбрать «Игнорировать текст вне таблицы», и тогда будет конвертирована только информация из блоков-таблиц. Это особенно полезно, если, скажем, нужно преобразовать в Excel PDF-прайс-лист какой-нибудь компании без логотипов и печатей.

Интеллектуальное преобразование PDF-файлов
Очень необычное, но важное нововведение. Некоторые сетевые сканеры со встроенными системами распознавания текста создают так называемые Searchable PDF. В нем имеется дополнительный невидимый слой, в который помещается распознанный текст. Если программа находит такой слой, то она чаще всего использует его, не тратя время на процесс распознавания. С другой стороны, содержимое этого слоя не всегда соответствует оригиналу, особенно если он содержит фрагменты на языках, не поддерживаемых OCR сканера. «Трансформер» проводит экспресс-анализ и для каждого абзаца принимает решение: извлечь текст из невидимого слоя или распознать изображение и получить текст заново.

Преобразование PDF-файлов с нестандартными шрифтами
Если в свойствах PDF-файла указаны нестандартные шрифты, то при «вытягивании» текста обычным образом вы получите «кракозябры» вместо букв. Для решения этой проблемы во второй версии появилась галочка «конвертировать как изображение» (рис. 6), что позволяет заново распознать весь текст даже в необычных шрифтах. В итоге вы получите распознанный текст в наиболее похожем стандартном шрифте Windows…
ОГОРОД КОЗЛОВСКОГО: ?
Автор: Козловский Евгений
То тут, то там, и в Москве, и в Питере, эффектно сделанные черные рекламные плакаты новой (первой!) сониевской цифровой зеркалки ? (альфа) просто не могли не броситься мне в глаза и запорошили их настолько, что я забыл кучу новостных сообщений и пресс-релизов по поводу происхождения этого аппарата и загорелся идеей протестировать новинку. И только когда, обратившись по этому поводу в московское представительство Sony, встретился там с Андреем Кургановым, — все сразу и вспомнил: и про перекупку Sony зеркалок у отказавшейся от фоторынка Konica Minolta, и о том, что полтора года назад уже встречался с Андреем Кургановым — правда, еще в офисе Konica Minolta — и брал у него на тестирование аппарат Dynax 7D, который и описал в «Огороде» "Тренировочные стрельбы", и даже о том, что пресловутая ? 100 — это не что иное, как даже не дочка, а скорее младшая сестрица того самого Dynax 7D. Отличия, однако, должны были быть (и оказались на самом деле), так что от идеи тестирования (скорее, конечно, — составления впечатления) я не отказался, о чем нисколько и не жалею.