Во многих случаях разные подходы комбинируются друг с другом, но путь от исследовательских разработок до коммерческих продуктов довольно долог. В настоящее время существует только один коммерческий пакет, «натасканный» на параллельных текстах, — машинный переводчик от небольшой компании Language Weaver. Google, победивший в августе на конкурсе НИСТ (см. табл. 3 и 4), тоже разрабатывает переводчик, который обучается на огромной библиотеке параллельных текстов, однако это внутренний проект, и когда он будет доведен до коммерческого уровня — неизвестно. Любопытен, кстати, выбор языков для конкурса. В 1950-х гг., в разгар холодной войны, в моде был русский язык, сейчас конкурсантам предлагаются задания на арабском и китайском. Language Weaver, к слову, также первым делом представила систему перевода с арабского на английский, но у нее свой интерес: государственные структуры во всех странах являются очень выгодным заказчиком, и разработчики систем машинного перевода, естественно, пытаются угадать их предпочтения.
Но сказать, что все эти новшества радикально решили проблему непонимания контекста, было бы преувеличением. В общем случае качество перевода и по сей день остается неудовлетворительным. Получить представление о содержании текста на иностранном языке с помощью машинного перевода вполне можно, но гарантий, что содержание это передано верно — никаких. Все современные системы требуют доработки либо исходного текста перед переводом (для уменьшения словаря, искоренения возможных двусмысленностей и предельного упрощения синтаксических конструкций), либо уже сделанного перевода до читаемого уровня. Кстати, переводчикам, которые этим занимаются, не позавидуешь — порой очень нелегко понять, что имелось в виду в оригинале, тогда как ошибки, которые делают при переводе люди, все же более предсказуемы. В защиту машин можно сказать, что, ошибаясь, они ошибаются одинаково и, найдя ошибку один раз, нетрудно проследить в тексте следующие ее вхождения.
Некоторого успеха добились исследователи, сделавшие ставку на упрощение и ограничение задачи. Еще в 1970-х гг. компания Caterpillar, пытаясь сократить расходы на перевод руководств к своей продукции, придумала оригинальный язык — Caterpillar Fundamental English. В каком-то смысле Caterpillar English можно назвать предшественником нашего «технического английского» — это был язык с предельно упрощенным синтаксисом и словарем из 850 слов. По задумке Caterpillar работники зарубежных филиалов компании должны были выучить этот новый вариант английского, чтобы иметь возможность читать руководства без перевода и по возможности без словаря. Из затеи с «выучить» ничего толком не вышло, но сама идея контролируемого языка, приложенная к написанию технических документов, привела к тому, что на свет появилась документация, которую машины могут переводить без особых потерь смысла. Конечно, никаких красот перевода тут ждать не приходится, но их и в оригинале, думается, немного.
В целом же технические тексты (на обычном, не упрощенном языке) вовсе не являются, как можно было бы подумать, желанным объектом для перевода. Несмотря на то что в них, как правило, используется довольно простой язык, отсутствуют идиомы и не очень много неоднозначных фрагментов. Технические тексты для машинного перевода неудобны тем, что довольно часто написаны «левой ногой», с грубыми грамматическими ошибками, а компьютер — в отличие от человека — не может заметить ошибку на языке исходника. Он переводит то, что дали, свято веруя, что исходный текст правильный во всех отношениях. И, конечно, ошибки, которые носителю языка кажутся шероховатостями, не меняющими общую картину, при переводе могут многократно усилиться и совершенно исказить смысл.
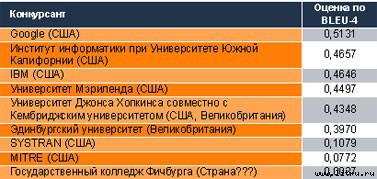
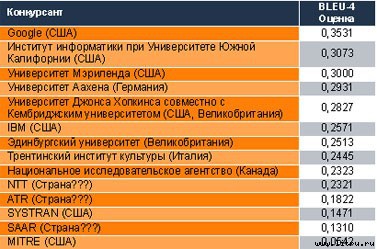
Рынок переводов сегодня оценивается примерно в 10 млрд. долларов. Машинам доверяют перевести только одну страницу из ста (то есть пара десятков крупных лабораторий, несколько серьезных софтверных компаний бьются между собой ради куска пирога в 100—150 млн. долларов). Два кризиса идей в теории МП (первый был в шестидесятых, второй — после короткого ренессанса в 80-х) и общее разочарование в моделях, обещавших когда-то создание эффективных компьютерных переводчиков, привели к тому, что многие специалисты сменили вектор исследований и теперь занимаются непосредственно проблемами обучения машин. Они учат компьютеры понимать.
Озорства ради мы решили проверить, как справляются с тестом Бар-Хиллела современные системы перевода, и попытались перевести историю про Джона с помощью известных онлайновых систем:
Маленький Джон искал его игрушечную коробку. Наконец, он нашел это. Коробка была в ручке. Джон был очень счастлив.
Маленький john смотрел для его коробки игрушки. Окончательно, он нашел его. Коробка находилась в пер. John был очень счастлив.
Прошло почти полвека, а коробку все никак не могут вытащить из ручки.
Окончательно, он нашел его. Я сошла с ума, какая досада.
Это же была бессловесная машина. Я сказал «бессловесная»? У нее были все органы чувств. Она даже могла говорить. Могла и говорила. Она болтала без передышки. И слушала все наши разговоры. Она читала через наши плечи и давала непрошеные советы, когда мы играли в покер. Порой нам хотелось убить ее, да вот убить робота нельзя… такого совершенного.
Описывая реально доступные сегодня технологии, мы старались не распыляться и уделили внимание лишь тем аспектам, которые, на наш взгляд, важны для построения диалоговых интерфейсов. Поэтому в разделе о машинном переводе обсуждается только полный автоматический машинный перевод (хотя есть разработки, предполагающие участие человека, — и у них качество перевода в целом выше), а в разделе о технологии распознавании речи лишь мельком упомянули о технологии распознавания голоса по телефонной линии, которая не особенно интересна в аспекте построения диалоговых интерфейсов, но коммерчески вполне успешна. Но все равно впечатление получается двойственное.
С одной стороны, мы уже многое умеем. И построить систему, которая будет поддерживать «светский разговор», давно не составляет труда. В этом году приз Лёбнера (за псевдопрохождение теста Тюринга) получил бот Jabberwocky, с которым можно разговаривать часами. И голос синтезировать у нас тоже получается хорошо (правда, не только за счет технологий, но и за счет человеческой способности к узнаванию образов). С распознаванием речи, конечно, дела обстоят не ахти, но научимся и распознавать.
То есть построить диалоговый интерфейс с заданными командами на уровне «открой файл», «сохрани изменения» и «закрой файл» мы можем уже сегодня (и такие продукты есть).
Тем не менее остается еще один, самый главный кирпичик. Если мы хотим, чтобы общение с компьютером было продуктивным, компьютер должен нас понимать. Собственно, natural language understanding — это огромное междисциплинарное направление, на которое и отдельной темы номера не хватит, но не нужно быть семи пядей во лбу, чтобы прийти к очевидному выводу: построение эффективных речевых коммуникаций невозможно без нахождения обоих собеседников в одном и том же контексте.
В разделе, посвященном машинному переводу, мы приводили пример с коробкой в ручке, но вот другой пример, никак не связанный с переводами. Допустим, у нас есть компьютер, загруженный по самое не хочу словарями, семантикой, лингвистическими правилами, статистическими алгоритмами и прочая, и прочая, и прочая. Что он ответит на элементарный вопрос «есть ли вода в холодильнике?» Нормальный компьютер, конечно же, ответит, что вода в холодильнике есть. Во всяком холодильнике в любой момент времени можно найти множество молекул воды. На любой вкус. При этом компьютер не путает определения (как он делал в случае с «pen»). Формально он прав. Но мы-то спрашивали совсем о другом.