Большинство гуглеров признали, что часто невозможно определить разницу в рейтингах в пределах одной десятой балла. Например, не удалось достичь консенсуса в различиях между 3,1 и 3,2. По словам сотрудницы нашей лаборатории по человеческим ресурсам и инновациям (People and Innovation Lab) Меган Хат, «возникала ситуация, когда рейтинги нельзя было считать ни надежными, ни валидными. Одному и тому же человеку с одной и той же производительностью можно было поставить как 3,2, так и 3,3, в зависимости от оценщика и группы калибровки. Это и означает ненадежность рейтинга. А если человек получает 3,3, когда на самом деле его результат не выше 3,2, то рейтинг тоже нельзя считать валидным, поскольку он не отражает реального положения дел».
Получается, рейтинги на самом деле, как говорила Меган, «группировались с ошибкой занижения или завышения». Мы должны были говорить: «Джим, твой рейтинг на уровне где-то между 3,3 и 3,5». Но на практике выходило иное. Менеджеры брали получившееся число и приписывали ему фактическое значение. Так, если кто-то показал результат между 3,3 и 3,5, менеджер мог решить, что это означает повышение производительности, хотя на самом деле человек работал на прежнем уровне. Представьте себе, насколько хуже будет, если ваш рейтинг упал, а вам говорят, что вы стали хуже работать, когда на самом деле имеет место ошибка измерений.
А потом произошло кое-что любопытное. Мы разбили 6200 гуглеров по восьми различным группам внутри компании. Но было решено разделить три из них общей численностью более 1000 человек еще на пять дополнительных категорий. Например, одна из групп получила три подкатегории в каждой категории, и звездным гуглерам стали присваивать рейтинги «великолепно в высокой степени», «великолепно в средней степени» и «великолепно в низкой степени». На графике ниже показано итоговое распределение рейтингов, хотя я свел все подкатегории в пять основных, чтобы четче была видна разница между двумя подходами. В группе А пять категорий, в группе Б — пятнадцать.
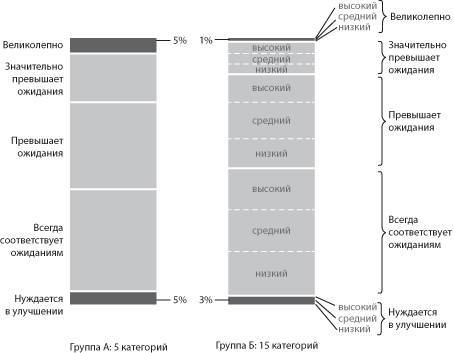
Средние рейтинги в группах А и Б
По группе Б, несмотря на большее количество категорий эффективности, которые, как мы надеялись, должны были сильнее высветить разницу между сотрудниками, на деле различий получилось гораздо меньше, чем в группе А. В группе А 5% получили оценку «великолепно», а в группе В — только 1%. При этом обе команды в целом работали с одинаковой эффективностью. Они вносили сравнимый вклад в дело Google, и люди в обеих командах обладали равными качествами. Просто за счет добавления лишних рейтинговых категорий, из которых можно было выбрать, сотрудники группы Б неосознанно, непреднамеренно и некорректно решили, что среди них почти нет «суперзвезд». Сами того не желая, они исключили 80% лучших работников (4 из 5) из высшей рейтинговой категории.
Сейчас вся Google перешла на пятибалльную шкалу. В конце 2013 г. все еще было на стадии эксперимента, но первые результаты обнадеживали. Во-первых, сотрудники получали более последовательную обратную связь вместо туманных различий между 3,2 и 3,3. Во-вторых, результатом стал более широкий разброс оценок. Когда мы сократили категории производительности, менеджеры начали активнее давать оценки с краев шкалы. Несмотря на недоказанность результатов академических исследований на тему систем оценки производительности и нейтральные отзывы самих гуглеров, мы решили, что пять категорий лучше множества, по крайней мере по двум вышеназванным причинам.
К середине 2014 г. мы наблюдали еще больше положительных результатов. Мы решили, что различные должности предоставляют разные возможности воздействия. Если вы инженер, то ваш новый продукт принесет пользу сотне или миллиарду человек. Если вы рекрутер, то, как бы вы ни старались, вам не хватит времени, чтобы повлиять на миллиард человек. Когда мы перестали указывать, как именно следует присуждать рейтинги рабочей эффективности, сформировались четыре разные схемы, которые лучше отражали реальные показатели производительности команд и сотрудников.
Кроме того, мы заметили, что менеджеры вдвое активнее стали присуждать рейтинги с краев шкалы. Тот факт, что больше сотрудников стали получать высший рейтинг, лучше отражал ситуацию (когда дочитаете до главы 10, узнаете, почему это так). А сократив по возможности в размерах «клеймо позора», связанное с пребыванием в нижней категории эффективности, мы упростили менеджерам возможность завязывать прямой, неравнодушный диалог с отстающими о том, как исправить ситуацию.
После долгих дебатов и страхов по поводу перемен мы заменили «непрецизионную» и затратную рейтинговую систему абсолютно новой, которая была и проще, и точнее, требуя при этом столько же времени на калибровку результатов. Ну, честно говоря, дебаты и страхи есть до сих пор! Мы над этим работаем. Но нам уже удалось увидеть, что люди более комфортно себя чувствуют при новой системе и выше ее оценивают.
Я делюсь здесь с вами этим нововведением, так сказать, в режиме бета-версии, точно так же как мы выпускаем продукты, которые уже могут принести гораздо больше пользы, чем существующие, но которые еще не на 100% совершенны.
И все-таки необходимо отметить, что вопрос о том, сколько рейтинговых категорий вы будете использовать, не самый важный, пусть даже гуглеры принимали его так близко к сердцу. Не нужно предлагать 15 с лишним рейтинговых ярлыков. А вот три или шесть — в самый раз. Считайте, я на вашей стороне.
Как обеспечить справедливый подход
Но у оценки производительности есть душа, и имя ее — калибровка. Справедливо будет заявить, что без нее наша процедура оценки была бы гораздо менее справедливой, эффективной и убедительной. Я уверен, именно благодаря калибровке гуглеры стали вдвое довольнее нашей рейтинговой системой, чем сотрудники в других компаниях своими.
Так что же это?
Отличие рейтинговой системы Google было (и есть) в том, что решение принимает не только непосредственный руководитель. Он присуждает сотруднику примерный рейтинг (скажем, «превосходит ожидания»), основываясь на великолепных результатах OKR, но с учетом и прочих факторов — скажем, количества проведенных собеседований или смягчающих обстоятельств вроде экономического кризиса, который влияет на прибыли[63]. Прежде чем этот примерный рейтинг получит статус итогового, группа менеджеров соберется вместе и рассмотрит все примерные рейтинги сотрудников в ходе процедуры, которую мы именуем калибровкой.
Калибровка — лишняя стадия в процессе, однако она крайне важна для обеспечения справедливости. Оценки менеджеров сравниваются с оценками, которые присуждают менеджеры аналогичных команд, а потом все менеджеры коллективно рассматривают показатели сотрудников. Собирается группа в количестве 5 или 10 менеджеров, выносит на общее обсуждение результаты своих сотрудников (50–1000), рассматривает их и совместно утверждает справедливые рейтинги. Это позволяет нам устранить давление на менеджеров со стороны подчиненных, которое может исказить оценки. Кроме того, при этом конечные результаты отражают общие ожидания по части рабочей эффективности, так как менеджеры зачастую имеют разные ожидания относительно своих подчиненных и поэтому интерпретируют стандарты рабочей эффективности в собственном стиле, не лишенном идиосинкразии. Помните школьные годы — у одних учителей было легко получить хорошую оценку, а у других… Калибровка устраняет предвзятость, побуждая менеджеров обосновывать свои решения друг перед другом. Кроме того, она усиливает у сотрудников ощущение справедливого подхода114.
Воздействие калибровки на присуждение людям рейтингов по природе своей не отличается от стимула, заставляющего рекрутеров сравнивать заметки после собеседований с кандидатами. Цель одна: устранить источники личной необъективности. Даже в небольшой компании вы получите лучшие результаты при довольных сотрудниках, если оценки будут присуждаться в ходе группового обсуждения, а не по воле одного-единственного руководителя.