Все изменилось в 1946 году. В тот год иезуитскому монаху по имени отец Роберто Буса пришла в голову отличная идея. Буса, изучавший творчество плодотворного теолога Фомы Аквинского, захотел создать конкорданс работ Аквината, который бы помогал ему в исследованиях. Компьютерная технология только начинала свое резкое восхождение, и Буса посчитал, что сможет создать конкорданс новым способом, «скормив» текст книги в одну из новых машин. Он отправился с этой идеей прямиком в IBM. Представители компании выслушали его и решили поддержать. Потребовались 30 лет и серьезная помощь со стороны IBM, однако со временем план Бусы сработал – в 1980 году был завершен монументальный Index Thomisticus[70]. Мир исследователей был впечатлен. Как и Index Хенли, Index Бусы позволил развиться новой области деятельности. Работа в этой области (известной в наши дни под названием цифровых гуманитарных наук) направлена на выявление того, каким образом компьютеры могут пригодиться для таких традиционных гуманитарных занятий, как история и литература[71].
Несмотря на всю важность этих индексов, их можно считать своего рода лебединой песнью. Колоссальная мощность современных компьютеров позволяет использовать для создания конкордансов одну-единственную строчку простого программного кода, который обеспечивает получение нужного результата за считаные секунды. К тому времени как Реймер опубликовала свой алфавитный эксперимент под названием Legendary, Lexical, Loquacious Love – представляющий собой, по сути, конкорданс, но без отсылок на номера страниц, – сам по себе процесс создания конкордансов перестал считаться серьезным занятием, заслуживающим признания. В наши дни ученые редко заботятся о том, чтобы создавать новые конкордансы. В этом нет нужды, поскольку даже дешевый ноутбук почти мгновенно найдет все случаи употребления определенного слова даже в длинном тексте. На первый взгляд, эпоха конкордансов ушла в прошлое.
Однако если вы поднимете крышку современных технологий, вас удивит увиденное внутри. Сегодняшний мир не может прожить без поисковых машин в Интернете, самых мощных инструментов поиска информации из когда-либо созданных. Что такое поисковая машина? По сути, она представляет собой список слов и страниц в сети Интернет, где эти слова появляются. За каждым крошечным белым поисковым окошком кроется огромный цифровой конкорданс.
Конкордансы не умерли со времен Бусы. Напротив, они завоевали этот мир.
Разделить розу на части и посчитать лепестки
Ципф был удивительным человеком, чья работа изменила множество областей знаний, некоторые из которых даже не входили в сферу его научных интересов. В наши дни сложно заниматься множеством вещей – от лингвистики до биологии, от городского планирования до физики процесса сыроварения, не сталкиваясь с наследием Ципфа. В своей работе Ципф подарил нам множество подсказок, необходимых для открытия секретов эволюции языка.
Но что же в этом довольно странном теоретике германской литературы превратило его, выражаясь научным языком, в пророка?
Джордж A. Миллер, один из основателей когнитивной психологии, как-то раз сказал о Ципфе интересную фразу, и нам кажется, что она позволяет в каком-то смысле ответить на этот вопрос. По мнению Миллера, Ципф был представителем «такого типа людей, которые разделяют розы на части, чтобы посчитать их лепестки» [72]. На первый взгляд это кажется не особенно лестным. Неужели Ципф так навязчиво занимался подсчетами, что не мог оценить красоту цветка?
Разумеется, нет. Ципф был знаменитым литературоведом, глубоко ценившим красоту и силу книги, этого цветка литературного гения. Однако Ципфа отличало то, что он не замыкался на этой красоте и мог оценить цветок с разных сторон. И один из таких способов как раз и состоит в том, чтобы разделить цветок на составные части.
До Ципфа книга была чем-то, что можно было прочитать и понять – строчку за строчкой и страницу за страницей. Ученые воспринимали ее гештальт полностью, как розу в период цветения. Даже Хенли, индекс которого помог Ципфу в его предприятии, предполагал, что его работа послужит помощником в традиционном чтении.
Однако Ципфа интересовало радикально новое понимание того, чем могла бы быть книга. Его великолепная интуиция подсказывала, что возможна и другая форма чтения – анализ небольших лепестков текста, избавление от их цветистого контекста и поиск свидетельств математической конструкции, лежащей в его основе.
В течение последнего столетия ученые активно следовали по пути, указанному этим гениальным провидцем. К моменту завершения анализа глаголов мы изрядно гордились тем, что относимся к этой группе исследователей. Но, честно говоря, мы были слишком захвачены особенностями неправильных глаголов, чтобы в полной мере оценить всю силу подхода Ципфа.
Но этому суждено было измениться. В конечном счете Ципф показал всем нам захватывающие научные горизонты, выбрав для этого ничтожную горстку цветов. Теперь благодаря Google оцифрованными оказались целые библиотеки, одна за другой. Мы хотели проделать то же, что сделал Ципф, но взять для этого не один, а все цветы.
Как правильно «гореть»
Изучая английский язык в своей родной стране, молодой француз learnt («выучил»), что некоторые глаголы произносились (spelt) по-разному в прошедшем времени. Эти «испорченные» (spoilt) глаголы обитали (dwelt) в своем собственном разделе учебника, выделяясь даже среди неправильных глаголов. Хотя заучить их все наизусть было невероятно сложно, он очень старался, запоминая список глаголов, прошедшее время которых образовывалось за счет добавления к основной форме – t вместо – ed.
Наконец-то оказавшись в Соединенных Штатах, студент был уверен в своем мастерском владении языком. Однако вскоре после своего прибытия, читая статью об Олимпийских играх в Лондоне, он с удивлением заметил следующий заголовок в газете Washington Post: Burned-out Phelps fizzles in Water Against Lochte («Выгоревший Фелпс выдыхается в воде под натиском Лохте»). Каждого француза учат, что глагол burn («гореть») – неправильный. В отношении Майкла Фелпса надо было сказать burnt out [73]. «Неужели в американских газетах нет корректоров?» – удивился он.
Вскоре он увидел еще один удивительный заголовок, на сей раз в Los Angeles Times: Kobe Bryant Says He Learned a Lot from Phil Jackson («Коби Брайант говорит, что многому научился у Фила Джексона») [74]. Студент ничего не знал о Филе Джексоне, но был шокирован тем, что для описания действий Коби использовалось слово learned. По правилам оно должно было звучать как learnt.
Постепенно студент понял, что, когда дело касается этого правила, все американцы делали одну и ту же ошибку. Он знал, что большинство американцев довольно скверно говорят по-французски, однако, если верить его учебникам, они были плохи и в своем родном языке. Он почуял (smelt) неладное.
К счастью, у него имелся доступ к новому виду «скопа». И вскоре он понял, что напрасно терял время на учебу во Франции.
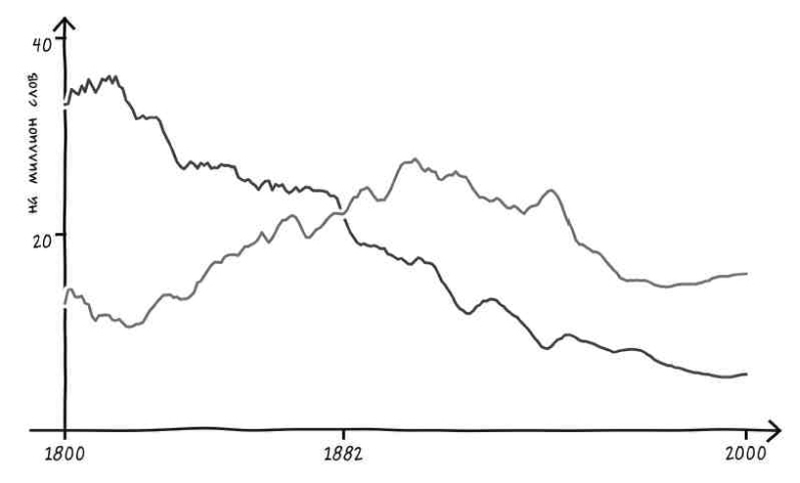
Что же случилось? Поскольку глаголы burn – burnt («жечь»), dwell – dwelt («обитать»), learn – learnt («учить»), smell – smelt («чуять»), spell – spelt («произносить»), spill – spilt («проливать») и spoil – spoilt («портить») следуют одному и тому же принципу, они сливаются в сознании говорящих по-английски людей. В результате они остаются неправильными в течение очень долгого времени – гораздо больше, чем можно было ожидать с учетом их индивидуальной частоты.