По всем названным причинам некоторые из самых важных ресурсов в истории знания людей о самих себе остаются во многом неиспользуемыми. Несмотря на то, что изучение социальных сетей проводится уже на протяжении десятилетий, мало что делалось в масштабах всей социальной сети Facebook, поскольку компании незачем делиться своими данными. Несмотря на то, что теория рынка существует уже несколько столетий, подробности сделок на основных онлайновых торговых площадках остаются в целом недоступными для экономистов (проведенное Левиным исследование eBay было исключением из правил). И, несмотря на тот факт, что люди потратили тысячелетия, чтобы придумать географические карты, изображения, созданные компаниями типа DigitalGlobe (снявшей поверхность Земли со спутников с разрешением 50 см), никогда не подвергались систематическому анализу. Если вдуматься, то такое несоответствие нашему обычно ненасытному желанию учиться и изучать шокирует. Для сравнения представьте себе ситуацию, при которой несколько поколений астрономов изучали бы далекие звезды, но не имели юридических прав смотреть на Солнце.
Тем не менее, зная, что на небе есть Солнце, мы не сможем побороть желание посмотреть на него. И поэтому в наши дни по всему миру происходит странный брачный танец. Исследователи и ученые обращаются к программистам, продукт-менеджерам и даже руководителям высшего звена корпораций за доступом к их данным. Бывает, первый этап переговоров проходит хорошо. Участники начинают встречаться за кофе. Так, слово за слово, через год на сцене появляется совершенно новый участник. И, к сожалению, чаще всего он оказывается юристом[30].
В попытках проанализировать имеющуюся у Google библиотеку всего мы были вынуждены найти способ для решения каждой из этих проблем. И должны признаться, что препятствия, связанные с цифровыми книгами, совсем не уникальны; по сути, они представляют собой всего лишь микрокосм, отражающий состояние больших данных в наши дни.
Культуромика
В настоящей книге мы расскажем вам о своей семилетней работе по количественной оценке исторических изменений. В результате мы создали новый вид «скопа» и предложили необычный, привлекательный и притягательный подход к языку, культуре и истории, который мы называем культуромикой[31].
Мы опишем множество наблюдений, которые стали результатом культуромического подхода. Мы поговорим о том, что показали нам обработанные данные в отношении изменений в английской грамматике, как в словарях возникают ошибки, как люди становятся знаменитыми, как правительства подавляют идеи, как общества учатся и забывают и как – совсем чуть-чуть – наша культура может вести себя детерминистическим образом, что дает возможность предсказать те или иные аспекты нашего общего будущего.
И, разумеется, мы представим вам наш новый «скоп» – инструмент, созданный нами вместе с Google и названный – по причинам, о которых мы расскажем в главе 3, – Ngram Viewer[32]. Выпущенный в 2010 году, Ngram Viewer позволяет создавать графики временных изменений частотности слов и идей. Этот «скоп» – и многочисленные расчеты, благодаря которым он возник, – представляет собой описанного во вступлении робота-историка. Вы можете поработать с ним самостоятельно прямо сейчас, зайдя на страницу http://books.google.com/ngrams. Результат наших трудов – это усердный робот, который круглосуточно используют миллионы людей всех возрастов по всему миру. Они стремятся понять историю по-новому – познавая непознанное.
Если коротко, то эта книга посвящена истории, которую рассказывают роботы, – истории о том, как выглядит человеческое прошлое под цифровой линзой. И хотя сегодня Ngram Viewer может показаться чем-то удивительным или небывалым, сама по себе цифровая линза пользуется огромным успехом, почти так же, как оптическая линза многие столетия назад. Из-за постоянно растущего цифрового следа каждый день появляются новые «скопы», открывающие прежде незаметные аспекты истории, географии, эпидемиологии, социологии, лингвистики, антропологии и даже биологии с физикой. Мир меняется. Меняется и то, как мы смотрим на мир и как воспринимаем все эти изменения.
Скольких слов стоит картинка?
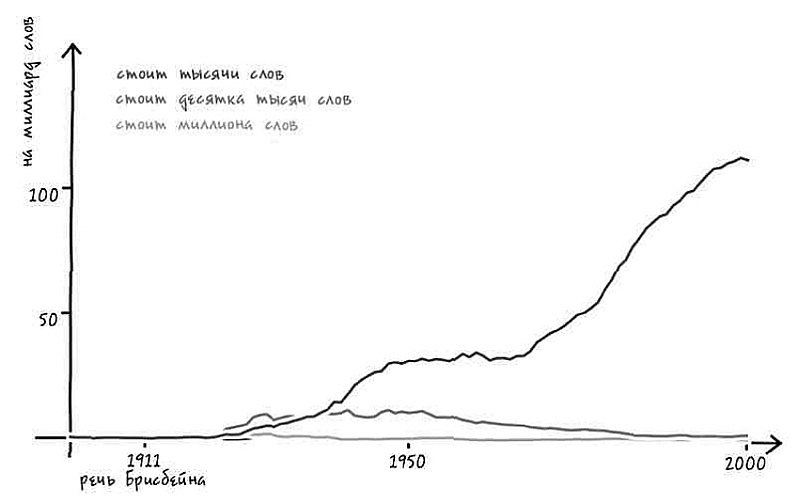
В 1911 году Артур Брисбейн, редактор одной американской газеты, в разговоре со специалистами по маркетингу произнес свою знаменитую фразу о том, что изображение «стоит тысячи слов». Не исключено, что он заявлял о «десятках тысяч слов». А может быть, речь шла о «миллионе слов»? В любом случае за несколько десятилетий это выражение приобрело популярность и – к возможному огорчению Брисбейна – теперь почему-то считается японской поговоркой (возможно, потому, что его слушатели отлично разбирались в маркетинге) [33].
Так что же сказал Брисбейн на самом деле? К сожалению, наш новый «скоп» вряд ли сможет найти первоисточник этого выражения. И на эту тему есть еще одна японская поговорка:
По сравнению со всеми произнесенными словами
Все отсканированные Google книги
Скромны, как хайку.
Тем не менее видно, как постепенно оформлялся брисбейновский принцип работы с изображениями в экономике.
Судя по всему, все три варианта – «тысяча слов», «десяток тысяч слов» и «миллион слов» – возникли практически одновременно после того, как Брисбейн произнес эту фразу. На протяжении следующих двух десятилетий они конкурировали между собой. Вариант «десяток тысяч» быстро вырвался в лидеры. Однако затем наступили 1930-е. Может быть, «десять тысяч» и «миллион» показались во времена Великой депрессии слишком заоблачными? Какова бы ни была причина, частота употребления варианта «картинка стоит тысячи слов» стала постепенно расти и в какой-то момент оставила конкурентов далеко позади.
Глава 2
Г. К. Ципф и охотники за окаменелостями
beautiful beautiful beautiful beautiful beautiful beautiful beautiful beautiful beautiful beautiful beautiful beautiful beautiful beautiful beautiful beautiful beautiful, beautiful, beautiful, beautiful, beautiful, beautiful, beautiful, beautiful, – beautiful. beautiful. beautiful. beautiful… beautiful…
В 1996 году концептуальная художница Карен Реймер опубликовала книгу Legendary, Lexical, Loquacious Love («Легендарная, лексическая, болтливая любовь»). И вот как она ее написала – она взяла полный текст любовного романа и расставила все его слова по алфавиту. Если слово встречалось в произведении несколько раз, то оно появлялось такое же количество раз в ее книге.
В книге отсутствуют синтаксис и предложения. По сути, это 345-страничный список слов, расположенных в алфавитном порядке. Она не похожа на связное повествование. Собственно говоря, когда вы ее читаете, она кажется полной бессмыслицей.
Мы редко читаем любовные романы, однако работа Реймер стала исключением. Она заставила нас пролистать ее целиком, поразив с первой страницы до последней, с драматического начала:
Глава 1
A
A A A A A A A A A A A A A A A A
A A A A A A[35]
И до потрясающего конца:
Глава 25
Z
zealous[36]
Двадцать пять глав, а не двадцать шесть: для буквы X главы не нашлось, поскольку в книге не было ни одного слова, начинавшегося с нее. В любовных романах встречаются откровенные элементы (то, что принято обозначать аббревиатурой XXX), но вот слова на эту букву встречаются в них крайне редко.